
The product data management team manually extracted and recorded information from thousands of fragrance product images-labels, packaging, bottles, and promotional materials. Each image required careful examination to capture brand names, product names, ingredient lists, volume specifications, batch numbers, and regulatory information.
This labor-intensive process was slow, error-prone, and inconsistent across team members. Manual transcription errors led to incorrect product catalogs, inventory mismatches, and compliance risks. The inability to scale data extraction bottlenecked new product launches and market expansions.
Problem Statement
THE CHALLENGE
Challenges
-
Time-Intensive Manual Extraction
3-5 minutes per product image for visual inspection and manual data recording.
-
Poor Image Quality
Blurry, motion-blurred, or low-resolution images from field captures made text reading difficult.
-
Complex Visual Conditions
Poor lighting, reflective surfaces, occlusions, and distracting backgrounds hindered accurate data capture.
-
Brand Recognition Challenges
Small, stylized, or partially obscured brand names and logos are difficult to identify consistently.
Solution
THE SOLUTION
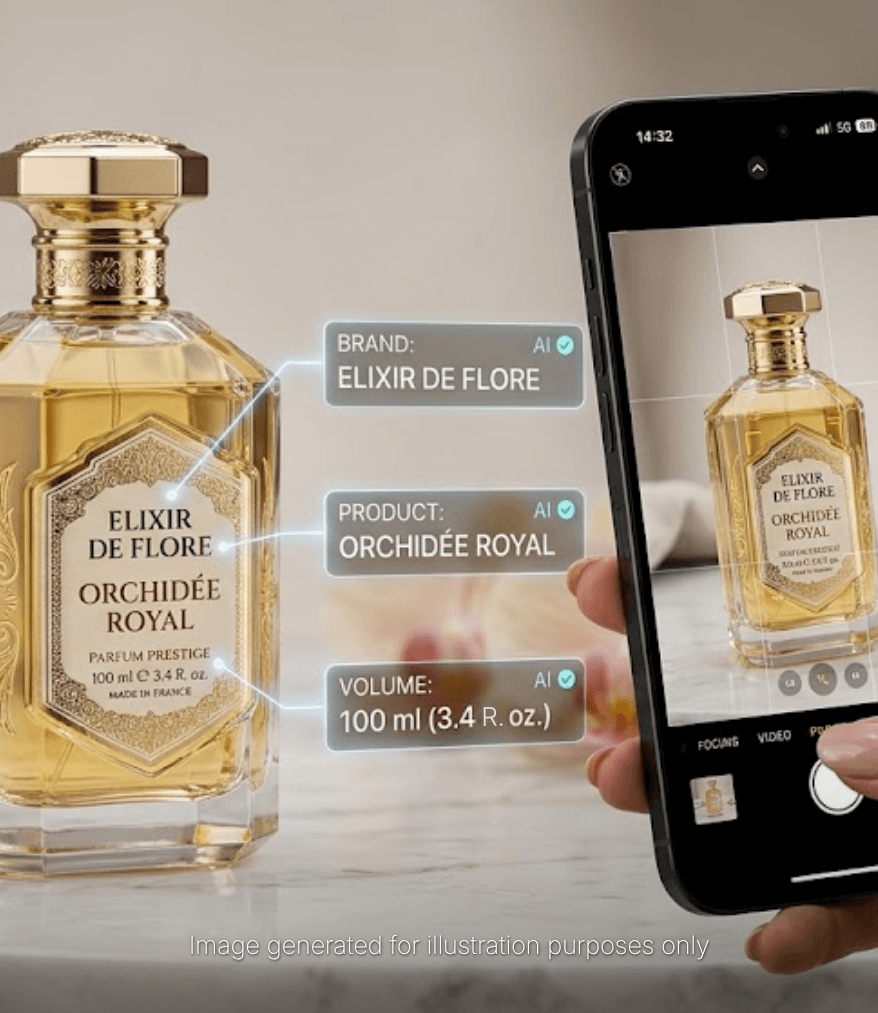
We developed an AI-powered image data extraction system combining OCR, NLP, and Large Language Models to automatically scan, extract, and structure product information from fragrance images. The system handles diverse image conditions, recognizes industry-specific text formats, and delivers structured data through an intuitive validation dashboard.
Flow: Image upload → OCR text extraction → NLP structuring → LLM interpretation → Data validation dashboard → Database integration
-
Fragrance domain training on label layouts, packaging formats, fonts, and text positioning specific to the fragrance industry.
-
OCR engine optimized for extracting text from challenging conditions-blurry images, reflective surfaces, curved bottles, stylized fonts.
-
NLP processing categorizes and tags extracted text into structured fields-product name, brand, ingredients, volume, batch number, regulatory info.
-
LLM enhancement improves accuracy by understanding context, correcting OCR errors, and filling incomplete data intelligently.
-
User-friendly dashboard displays extracted data for quick review, validation, and correction before database integration.










